ポイント
- 高性能な蛍光免疫センサーを見分ける分類モデルを深層学習により構築。
- アミノ酸の配列情報のみから8割以上の的中率で機能向上に有望な変異を予測。
- インシリコでのスクリーニングによりわずか数日で高性能化を達成。
概要
東京科学大学 総合研究院 化学生命科学研究所の北口哲也准教授と朱博助教、生命理工学院の井上暁人大学院生(研究当時)らの研究チームは、同工学院の小林健准教授と米国カリフォルニア大学アーバイン校のChang C. Liu教授と共同で、蛍光免疫センサーを高性能化させる独自の深層学習モデル「NanoQ-model 1.0」を構築しました。
標的分子を検出できる免疫センサーは、環境調査や食品分析、医療などで不可欠です。しかし、高感度なセンサーの開発には膨大な試行錯誤が必要で、数ヵ月を要していました。本研究では、深層学習を利用して構築した分類モデルにより、このプロセスをわずか数日に短縮することに成功しています。
今回の対象はクエンチ抗体(Q-body)[用語1]と呼ばれる蛍光免疫センサーです。Q-bodyは、抗体のN末側が蛍光色素で標識されており、抗原が結合すると蛍光色素のクエンチ(消光)が解除され、蛍光が上昇します。したがって、蛍光色素が強く消光する抗体ほど大きい蛍光応答が期待できますが、この消光効果は抗体ごとに異なり、予測が極めて困難でした。
研究チームは、酵母を用いたスクリーニングによって、消光効果を基準にして抗体ライブラリーをFACS[用語2]で分類し、それぞれのプールを次世代シーケンス解析[用語3]したのち、アミノ酸配列を使ってタンパク質言語モデルProtBert-BFD[用語4]を再学習させ、高性能なQ-bodyとなるアミノ酸配列を予測できる独自モデルを構築しました。このモデルを新型コロナウイルス(SARS-CoV-2)に結合する抗体で検証したところ、予測された変異の8割以上で消光が強まり、検出感度の向上も確認できました。
このモデルの誕生により、免疫センサー開発が飛躍的に加速するだけでなく、将来的にはアミノ酸配列だけで目的の機能を持つかどうかの見極めが可能となり、タンパク質エンジニアリングの新たな可能性を切り拓くと期待されます。
本研究成果は、2024年2月9日付の「JACS Au」誌にオンライン掲載されました。
背景
免疫センサーは、抗原抗体反応を利用した高感度な検出ツールで、さまざまな分野で活躍しています。例えば、環境調査での水や空気中の有害物質の検出や、食品分析でのアレルゲンや添加物のチェックに役立っています。さらに、医療や臨床検査では、感染症や病気の診断にも応用されるなど、私たちの健康と安全を支えています。
研究チームはこれまでに、クエンチ抗体(Q-body)と呼ばれる蛍光免疫センサーを開発してきました。Q-bodyは、抗体のN末側の抗原結合部位近くにTAMRAなどの蛍光色素を標識したセンサーで、洗浄工程を必要とせず、試料と混ぜるだけで標的分子の検出や定量が可能です。通常の抗原がない状態では蛍光がクエンチ(消光)されていますが、抗原が結合すると消光が解除され、蛍光が強まる仕組みになっています。すなわち、消光が強いほど抗原の有無による蛍光の変化(蛍光応答)が大きくなるため、高性能なQ-bodyを開発するには、消光の弱い抗体を強くする工夫や、もともと消光が強い抗体を選択することが重要となります。
これまでの研究で、Q-bodyの消光には、抗原結合部位を構成する相補性決定領域(CDR)[用語5]の特定のアミノ酸、特にトリプトファン(Trp)残基が大きく関与していることがわかっています。しかし、Trp残基の位置や周囲のアミノ酸配列によって消光の程度が大きく異なるため、抗体のアミノ酸配列を見ただけで高性能な免疫センサーになるかどうかを予測するのは困難でした。もし予測が可能となれば、従来の試行錯誤にかかっていた時間と労力を大幅に削減でき、迅速かつ効率的なセンサー開発が可能となります。
研究成果
研究グループは深層学習を駆使して、高性能なQ-bodyとなる抗体をCDRのアミノ酸配列から予測できる独自のモデルを構築することを目指しました。これが実現すれば、新たな標的分子に対する抗体を用いてセンサーの開発するときに、短期間で感度を向上させることが可能となります。
1)データセットの準備
本研究ではまず、Q-bodyの消光を予測するためのモデル構築に向け、消光効果とアミノ酸配列とが対応したデータセットを準備しました。具体的には、ラクダ科由来の重鎖抗体断片(ナノボディ)にコイルドコイル[用語6]を融合させたライブラリーを作製し、酵母細胞に提示しました。次に、結合させるコイルドコイルペプチドを合成し、FITCとTAMRAで修飾しました。この修飾ペプチドとナノボディ提示酵母を混合し、二量体化による強固な結合を利用して、酵母表層上でQ-bodyを作製しました。消光効果は、TAMRAが抗体によって消光されていないときは赤色蛍光が、逆に消光されているときはFITCの緑色蛍光が強く発せられることにより、正確に評価できます。Q-bodyを提示した酵母をFACSによって弱い消光と強い消光の2つのプールに分類した結果、弱い消光プールでは赤色蛍光が強く、強い消光プールでは緑色蛍光が強いことが確認でき、消光効果によって明確に分類できました(図1)。
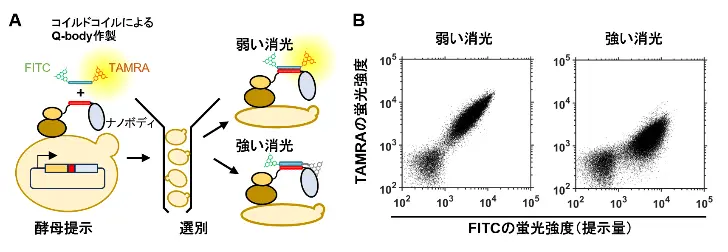
DOI:10.1021/jacsau.4c01189より一部改変
2)消光効果を予測するモデルの構築
次に、弱い消光と強い消光で分類した2種類の酵母プールから、次世代シーケンス解析を用いて 104種類程度のナノボディDNA配列を決定し、それらをアミノ酸配列へと変換しました。この消光で分類されたアミノ酸配列データの80%を学習用、20%を評価用に分けました。そして学習用データを活用し、事前学習済みのタンパク質言語モデルProtBert-BFDを再学習させることで、CDRのアミノ酸配列から消光の有無を予測できる独自のモデルの構築に取り組みました(図2A)。
ナノボディには3つのCDRが存在するため、まずCDRごとに個別の分類モデルを構築し、予測精度を比較しました。それぞれの分類モデルについて、評価用のデータを活用して適合率-再現率(PR)曲線[用語7]のAUC値を検討したところ、CDR3を用いた分類モデルが最も高い予測精度を示し、次にCDR1が高いことが明らかになりました。
さらに、探索可能なアミノ酸配列空間を拡大するために、CDR1とCDR3を組み合わせた分類モデル(CDR1+3モデル)を構築したところ、CDR3単独モデルよりも高い予測精度を示しました(図2B、C)。これにより、予測精度と探索可能な配列空間のバランスが取れたモデルの構築に成功し、このCDR1+3モデルを 「NanoQ-model 1.0」と命名しました。
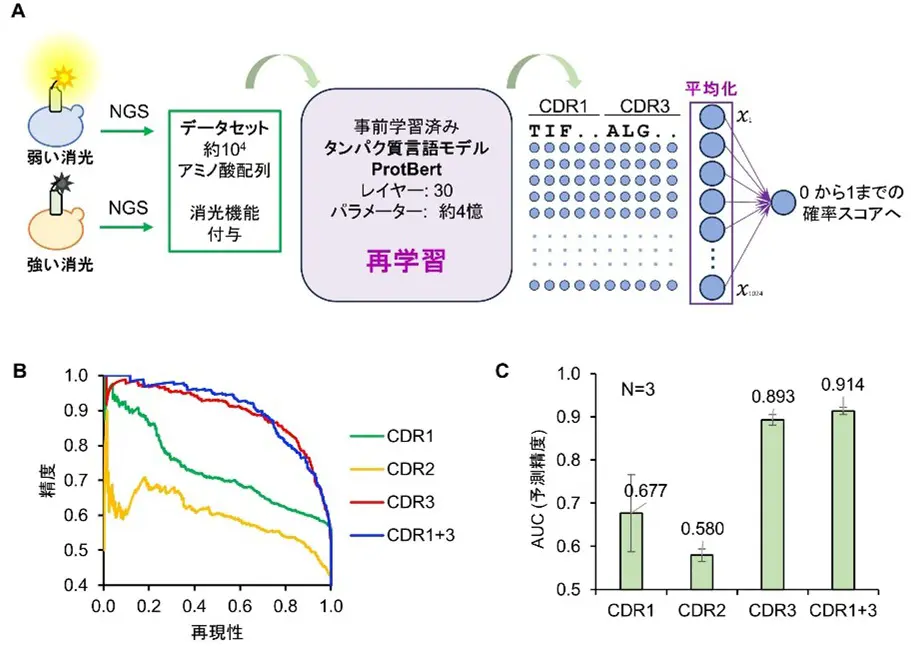
DOI:10.1021/jacsau.4c01189より一部改変
3)モデルを用いたインシリコによるスクリーニング
次に、構築した「NanoQ-model 1.0」を用いて、消光を強めるアミノ酸変異のインシリコ[用語8]によるスクリーニングを行いました。本モデルは、入力されたCDR1およびCDR3のアミノ酸配列を解析し、消光の確率スコアを出力します。このスコアが大きいほど、より強い消光効果を持つ変異であると予測されることを意味します。予測には、同じナノボディライブラリー由来の新型コロナウイルスの受容体結合ドメイン(RBD)[用語9]を標的とする、2種類のナノボディ(RBD1i13、RBD10i14)を使用しました。RBD1i13は、消光に重要とされるトリプトファン(Trp)残基を持たないため、TrpをCDR内の全ての位置に1つずつ導入し、その影響を解析する手法(Trpスキャニング)で予測しました。一方、CDR3にTrpを1つ持つRBD10i14では、すべての位置でTrpを除いた19種類のアミノ酸を順に導入する手法(単一部位飽和変異)で予測しました(図3A)。今回の研究では、Trp残基の数を1つに限定し、その影響を明確に理解することを目指しました。
構築したモデルによる予測によると、RBD1i13とRBD10i14の両方で、野生型に比べて高い確率スコアを示す変異がCDR3に集中していることが明らかになりました。また、CDR1では顕著な消光効果はほとんど見られませんでした。それぞれのナノボディの予測において、このあとの消光の予測に対する検証実験のために、消光の確率スコアが特に高いアミノ酸変異が得られた場所を3か所ずつ選択しました。選択した場所は、RBD1i13では107、113、115番目、RBD10i14ではアミノ酸の挿入が1か所あるため、112.1、112、114、116番目となります(図3B、C)。
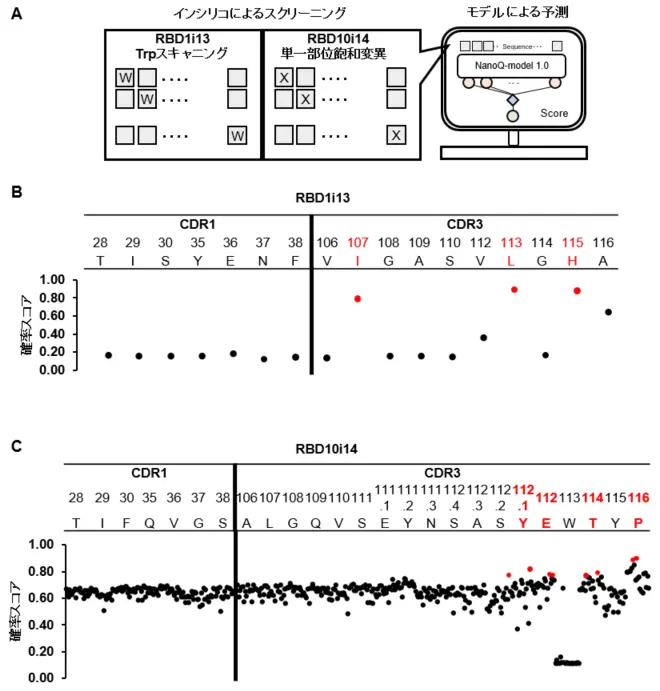
DOI:10.1021/jacsau.4c01189より一部改変
4)モデルによる予測的中率の検証
「NanoQ-model 1.0」による予測を検証するために、RBD1i13の3か所にはTrpを、RBD10i14の4か所には消光の確率スコアが最も高かった2種類のアミノ酸変異を導入し、酵母表層上でQ-bodyを作製しました。それぞれの消光効果をフローサイトメトリー[用語10]で検証したところ、11種類の変異体のうち9種類が予測と一致し、8割以上の的中率で消光が強まる結果が得られました(図4A-C)。さらに、ナノボディではなく、マウス抗体由来のQ-body重鎖に変異を導入した既報データでも検証したところ、7割程度の的中率を示し、本モデルに一定の汎用性があることが示されました。
さらに、消光効果が予測と一致した9種類の変異体のうち、抗原結合能が維持されていた3種類を選択し、大腸菌を使ってナノボディを産生、精製しました。このナノボディを蛍光色素TAMRAで標識してQ-bodyとしての機能を検証したところ、いずれの変異体においても野生型と比べて蛍光応答と検出限界が向上していました(図4D, E)。
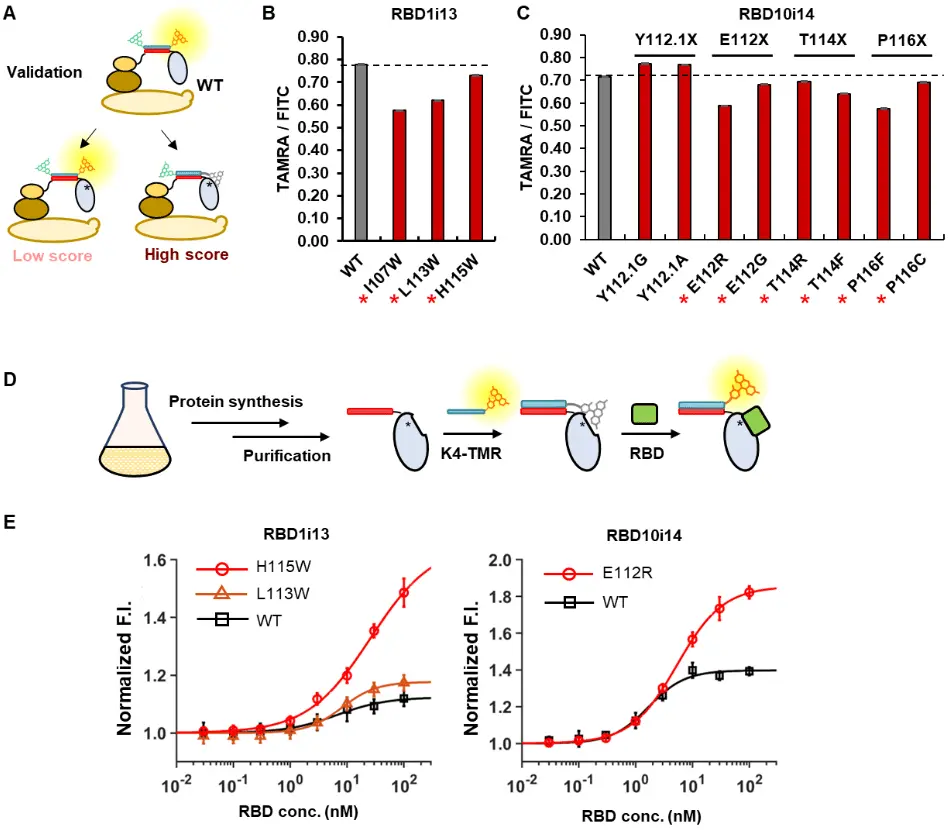
DOI:10.1021/jacsau.4c01189より一部改変
社会的インパクト
本研究は、インシリコでのスクリーニングを行う深層学習モデル「NanoQ-model 1.0」の構築により、これまで数ヵ月を要していた高性能のQ-bodyの開発を数日まで短縮させることに成功しました。このモデルは、蛍光免疫センサーQ-bodyの開発プロセスを劇的に加速し、多検体のハイスループット診断や自宅での遠隔健康診断といった次世代医療の最前線を支えることが期待されます。さらに、本研究で確立したモデル構築手法は、Q-bodyにとどまらず、あらゆるバイオセンサーの開発に応用可能であり、抗体を含む多様な結合タンパク質から革新的なバイオセンサーを創出する鍵となります。本モデルはGitHub(公開リンク)で公開されています。
公開リンク(Git Hub):NanoQ-Model 1.0
今後の展開
本研究で構築したモデルは、アミノ酸配列のみからタンパク質の機能の有無を予測する、まさに“機能予測AI”とも言える革新的なツールへの第一歩です。今後はさらに、タンパク質のアミノ酸配列と、酵素活性やリガンド結合能といった特定の機能を対応させて学習させたモデルを数多く構築することで、アミノ酸配列を入力すればそのタンパク質がどのような機能を持つのかを予測できるようになります。これは単なる予測を超え、意図した機能を持つタンパク質をゼロから創り出す未来へとつながります。さらに生命科学だけでなく、医療・環境・エネルギーなど幅広い分野で社会に貢献する可能性を秘めた、次世代のバイオデザインへの道を切り拓くことができます。
付記
本研究は、科学研究費助成事業(課題番号:JP22H05176、JP24K01264、 JP21K14468、JP24H01123、JP23K13607、JP21J21386 、JP22KJ1271)、東京科学大学総合研究院「プレ研究ユニット制度」、東京科学大学基礎研究機構「新研究展開奨励金」、物質・デバイス領域共同研究拠点「共同研究プログラム」、東京科学大学「リーダーシップ・オフキャンパスプロジェクト(ToTAL)」の支援を受けて行われました。
用語説明
- [用語1]
- クエンチ抗体(Quenchbody; Q-body):N末側に蛍光色素標識された抗体あるいは抗体断片。抗原が結合していないとき、蛍光色素は抗体内のトリプトファンからの光誘起電子移動によって消光状態となるが、抗原が結合すると消光が解除される。
- [用語2]
- FACS(Fluorescence-Activated Cell Sorting):細胞などの不均一な粒子状の混合物を蛍光特性などによって分離する技術。今回は蛍光標識した酵母細胞をTAMRAとFITCの蛍光強度により分類している。
- [用語3]
- 次世代シーケンス解析:DNAやRNAなどの遺伝子やゲノムの配列を高速かつ大規模に解読する技術。従来用いられているサンガー法よりも効率的で、同時に多数のサンプルを解析できる。今回はナノボディのライブラリーという大量のDNA配列を決定するために用いている。
- [用語4]
- ProtBert-BFD:タンパク質言語モデルの一種。データベースに登録されたタンパク質配列を使って事前学習を行っており、今回のようにアミノ酸配列と目的の機能を対応させたデータセットで再学習し、教師あり学習を実施することができる。
- [用語5]
- 相補性決定領域(Complementarity-determining region; CDR):抗体の可変鎖の一部で、抗体間での相同性が低く、特異的な抗原結合への貢献が大きい領域。1つの可変鎖には3つのCDRが含まれているため、ナノボディには3つ、IgGには6つ存在する。
- [用語6]
- コイルドコイル:2本以上のαヘリックスがらせん状に巻きついて形成されるタンパク質の構造。安定性が高く、強固に相互作用するものも数多く見られる。今回はE4とK4の相互作用を利用して、ナノボディに蛍光色素を標識している。
- [用語7]
- 適合率-再現性(Precision-recall; PR)曲線:機械学習モデルの評価でよく用いられる、縦軸に適合率(Precision)、横軸に再現率(Recall)を取ってプロットした場合の曲線。適合率は陽性的中率とも呼ばれ、陽性の予測が重要な場合によく用いられる。
- [用語8]
- インシリコ:計算を使って結果を予測する方法。in silicoは直訳すると「シリコンの中で」であり、実際には「コンピュータの中で」という意味で使われる。これは、in vivo(生きた体の中で)やin vitro(試験管の中で)といった言葉と同様に使われる。
- [用語9]
- 新型コロナウイルスの受容体結合ドメイン(Receptor-binding-domain; RBD):ウイルスのスパイクタンパク質の中にある、ヒトの細胞表面にあるACE2受容体と結合する役割を持つ領域。ウイルスの感染に重要な領域であることから、ワクチンや抗体医薬の標的としても注目されている。
- [用語10]
- フローサイトメトリー:細胞などの不均一な粒子状の混合物を液体の中で流しながら、レーザー光を当てて特徴を測定する技術。今回は蛍光標識した酵母細胞のTAMRAとFITCの蛍光強度を測定している。特徴を測定したあと、分離する技術が用語2のFACSである
論文情報
- 掲載誌:
- JACS Au
- タイトル:
- Prediction of Single-Mutation Effects for Fluorescent Immunosensor Engineering with an End-to-End Trained Protein Language Model
- 著者:
- Akihito Inoue,# Bo Zhu,# Keisuke Mizutani, Ken Kobayashi, Takanobu Yasuda, Alon Wellner, Chang C. Liu, Tetsuya Kitaguchi*